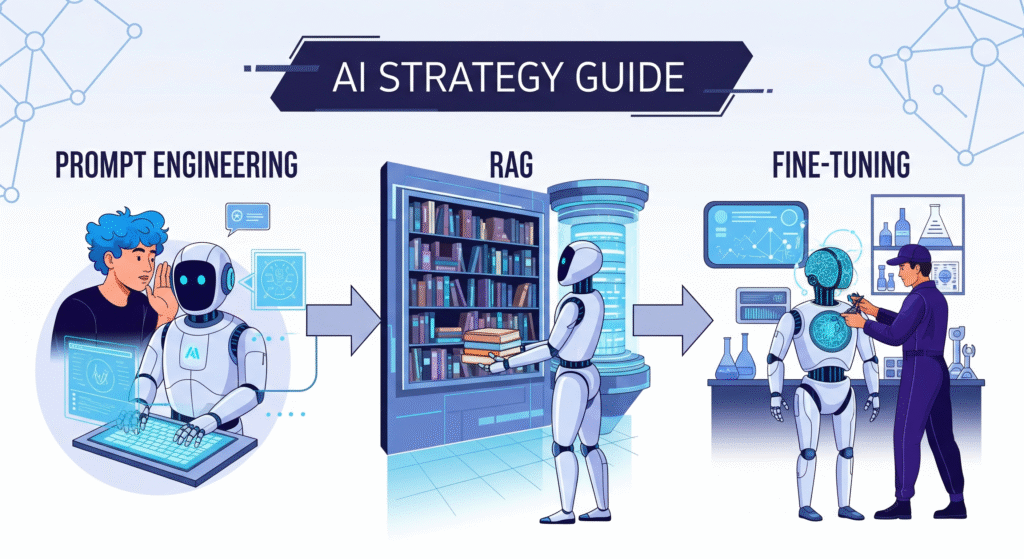
When building AI applications, three key techniques dominate the landscape: Prompt Engineering, RAG (Retrieval-Augmented Generation), and Fine-tuning. Understanding when and how to use each technique can make the difference between a good AI application and a great one.
This guide breaks down these concepts using simple analogies and practical examples to help you choose the right approach for your specific use case.
Overview: The Three AI Techniques
graph TD
A[AI Application Techniques] --> B[Prompt Engineering<br/>💡 Smart Questioning]
A --> C[RAG<br/>📚 Research Assistant]
A --> D[Fine-tuning<br/>🎯 Personalized AI]
B --> B1[Direct LLM + Optimized Prompts<br/>Quick & Cost-effective]
C --> C1[External Knowledge + Vector Search<br/>Current & Private Data]
D --> D1[Custom Model Training<br/>Specialized Behavior]
Each technique serves different purposes and comes with its own trade-offs in terms of cost, complexity, and capabilities. The key is understanding which approach best fits your specific requirements and constraints.
1. Prompt Engineering: The Art of Smart Questioning
Understanding Through Analogy
Imagine you have a brilliant but literal-minded assistant who can answer almost any question, but the quality of their response depends entirely on how you frame your question. This is essentially what prompt engineering is about – crafting your inputs to get the best possible outputs from a pre-trained language model.
The Difference Good Prompting Makes:
Poor Prompt:
"Write about marketing."
Result: Generic, unfocused content that could apply to any business or industry.
Engineered Prompt:
"You are an experienced B2B SaaS marketing director. Write a 300-word strategy overview for launching a new project management tool to small businesses. Focus on digital channels, include 3 specific tactics, and address the main objection of 'we already have a solution.'"
Result: Specific, actionable content tailored to your exact needs.
Core Principles of Effective Prompt Engineering
- Role Definition and Context Setting Always establish who the AI should be and what context it’s operating in. This dramatically improves response quality and consistency.
- Structural Guidance Specify the format, length, and structure you want. Whether it’s bullet points, a formal report, or casual conversation, being explicit helps.
- Example-Driven Instructions Show the AI what you want through examples. This is particularly powerful for maintaining consistency across multiple outputs.
- Constraint Specification Define what the AI should and shouldn’t do. This includes tone, content boundaries, and response limitations.
- Iterative Refinement Prompt engineering is inherently iterative. You’ll refine your prompts based on the outputs you receive.
Advanced Prompt Engineering Techniques
- Chain-of-Thought Prompting: Ask the AI to work through problems step-by-step, showing its reasoning process.
- Few-Shot Learning: Provide multiple examples of input-output pairs to establish patterns.
- Prompt Chaining: Break complex tasks into smaller prompts that build on each other.
- Negative Prompting: Explicitly state what you don’t want to avoid common mistakes.
When Prompt Engineering Works Best
Prompt engineering is ideal when you need quick results, have limited resources, or are working with general-purpose tasks that don’t require specialized knowledge. It’s perfect for content creation, basic analysis, coding assistance, and creative tasks where the pre-trained model’s knowledge is sufficient.
However, it has limitations. You can’t teach the model new facts, access real-time information, or fundamentally change its behavior patterns. For these needs, you’ll want to consider RAG or fine-tuning.
2. RAG: Your AI Research Assistant
The Knowledge Enhancement Approach
RAG (Retrieval-Augmented Generation) solves one of the biggest limitations of standard language models: they only know what they were trained on, and that knowledge has a cutoff date. RAG gives your AI access to external, up-to-date, and private information by combining retrieval systems with generation capabilities.
flowchart TD
A["🔍 User Query<br/>What's our return policy<br/>for electronics?"]
A --> B["📊 Vector Search<br/>Convert query to embeddings<br/>Search similarity"]
B --> C["💾 Company Database<br/>📋 Policies<br/>❓ FAQs<br/>📄 Documents"]
C --> D["📤 Retrieved Context<br/>Electronics: 30-day return window<br/>Original receipt required<br/>Condition must be new"]
D --> E["🤖 LLM Processing<br/>Query + Retrieved Context<br/>Generate response"]
E --> F["✅ Accurate Response<br/>Based on current company policies<br/>Includes specific details<br/>Cites relevant sources"]
style A fill:#e1f5fe
style B fill:#f3e5f5
style C fill:#e8f5e8
style D fill:#fff3e0
style E fill:#fce4ec
style F fill:#e0f2f1How RAG Really Works
- Step 1: Document Processing and Storage Your documents, policies, product information, or any text-based knowledge gets processed into vector embeddings – mathematical representations that capture meaning and context. These vectors are stored in a specialized database that can quickly find similar content.
- Step 2: Query Processing When a user asks a question, their query is also converted into a vector embedding using the same process.
- Step 3: Similarity Search The system searches through your vector database to find the most relevant information related to the user’s query. This isn’t just keyword matching – it understands semantic similarity.
- Step 4: Context Assembly The most relevant documents or sections are retrieved and formatted as context for the language model.
- Step 5: Enhanced Generation The language model receives both the user’s original question and the retrieved context, allowing it to generate responses based on your specific information rather than just its training data.
Types of RAG Implementations
- Simple RAG: Direct retrieval and generation – good for straightforward Q&A systems.
- Advanced RAG: Includes query rewriting, multi-step retrieval, and answer verification for more complex scenarios.
- Multi-Modal RAG: Can work with text, images, and other data types for comprehensive information retrieval.
- Conversational RAG: Maintains context across multiple turns in a conversation while still accessing external knowledge.
Real-World RAG Applications
Customer Support Systems: Access to product manuals, troubleshooting guides, and company policies ensures accurate, current responses.
Internal Knowledge Management: Employees can query company documents, procedures, and institutional knowledge through natural language.
Legal and Compliance: Access to current regulations, case law, and compliance documentation with the ability to cite sources.
Technical Documentation: Software engineers can query codebases, API documentation, and technical specifications.
RAG Implementation Considerations
Data Quality: Your RAG system is only as good as the information you feed it. Poor, outdated, or incomplete documentation will lead to poor responses.
Chunk Size and Strategy: How you break up your documents affects retrieval quality. Too small and you lose context; too large and you dilute relevance.
Vector Database Choice: Different vector databases have different strengths in terms of speed, accuracy, and scale.
Retrieval Strategy: Simple similarity search might not be enough for complex queries that require multiple pieces of information.
3. Fine-tuning: Creating Your Specialized AI
Beyond Generic AI
Fine-tuning takes a pre-trained language model and trains it further on your specific data to create a model that behaves exactly how you want it to. Think of it as taking a generally educated person and giving them specialized training for your specific role and company culture.
flowchart TD
A["🎯 Pre-trained LLM<br/>General knowledge<br/>Broad capabilities<br/>Generic responses"]
A --> B["📊 Custom Training Data<br/>Company conversations<br/>Brand voice examples<br/>Domain-specific content<br/>Desired response patterns"]
B --> C["⚙️ Fine-tuning Process<br/>Update model weights<br/>Specialized training<br/>Parameter adjustment"]
C --> D["🔧 Model Customization<br/>LoRA/PEFT techniques<br/>Full fine-tuning<br/>Instruction tuning"]
D --> E["🧪 Evaluation & Testing<br/>Performance metrics<br/>Behavior validation<br/>Quality assessment"]
E --> F["🚀 Specialized AI Model<br/>Custom behavior<br/>Brand-specific responses<br/>Domain expertise<br/>Consistent performance"]
G["💾 Requirements"] --> B
H["🖥️ GPU Resources<br/>Technical expertise<br/>Training infrastructure"] --> C
I["📈 Monitoring<br/>Performance tracking<br/>Continuous improvement"] --> F
style A fill:#e3f2fd
style B fill:#f1f8e9
style C fill:#fff3e0
style D fill:#fce4ec
style E fill:#f3e5f5
style F fill:#e0f2f1
style G fill:#ffebee
style H fill:#e8eaf6
style I fill:#e1f5feThe Fine-tuning Process Explained
- Data Collection and Preparation: You need high-quality examples of the behavior you want. This might be thousands of conversation examples, writing samples in your brand voice, or domain-specific question-answer pairs.
- Training Configuration: Deciding which parts of the model to update, how aggressively to train, and for how long. This requires significant technical expertise.
- Evaluation and Iteration: Testing the fine-tuned model against your goals and refining the training data and process.
- Deployment and Monitoring: Running your custom model and monitoring its performance over time.
Types of Fine-tuning
Full Fine-tuning: Updates all the model’s parameters. Most expensive but gives maximum control.
Parameter-Efficient Fine-tuning (PEFT): Techniques like LoRA that update only small portions of the model, reducing cost while maintaining effectiveness.
Instruction Tuning: Specifically training the model to follow instructions better, often using techniques like RLHF (Reinforcement Learning from Human Feedback).
Domain Adaptation: Training the model on domain-specific data to improve performance in specialized fields like medicine, law, or finance.
When Fine-tuning Makes Sense
- Consistent Brand Voice: When every interaction needs to reflect your company’s specific communication style and values.
- Specialized Domains: For applications in fields like medical diagnosis, legal analysis, or technical support where generic models lack the necessary expertise.
- Behavioral Consistency: When you need predictable responses that align with specific guidelines or policies.
- Performance Optimization: When prompt engineering and RAG aren’t sufficient to achieve the quality or consistency you need.
Fine-tuning Challenges and Considerations
- Resource Requirements: Fine-tuning requires significant computational resources, specialized hardware, and technical expertise.
- Data Requirements: You need large amounts of high-quality training data that represents the behavior you want.
- Maintenance Overhead: Fine-tuned models need ongoing monitoring, evaluation, and potentially retraining as requirements change.
- Version Control: Managing different versions of your custom model and ensuring consistency across deployments.
4. Choosing the Right Approach: A Decision Framework
Cost and Complexity Analysis
| Aspect | Prompt Engineering | RAG | Fine-tuning |
|---|---|---|---|
| Initial Cost | Very Low | Medium | High |
| Ongoing Cost | Low | Medium | Medium-High |
| Technical Complexity | Low | Medium | High |
| Time to Deploy | Hours-Days | Days-Weeks | Weeks-Months |
| Customization Level | Limited | Moderate | Complete |
| Maintenance Effort | Low | Medium | High |
| Scalability | High | High | Medium |
| Data Requirements | None | Moderate | High |
Decision Tree for Technique Selection
flowchart TD
A[What's your primary goal?] --> B{Current/Private<br/>Information?}
A --> C{Specialized<br/>Behavior?}
A --> D{Quick General<br/>Results?}
A --> E{Unlimited Budget<br/>+ Custom Needs?}
B -->|Yes| F[RAG<br/>📊 Policies, Catalogs<br/>📰 News, Documents]
C -->|Yes| G[Fine-tuning<br/>🎯 Brand Voice<br/>🔬 Domain Expertise<br/>📝 Response Patterns]
D -->|Yes| H[Prompt Engineering<br/>✍️ Content Creation<br/>📈 Basic Analysis<br/>❓ General Q&A]
E -->|Yes| I[Hybrid Approaches<br/>🔄 Combine Techniques<br/>⚡ Maximum Effectiveness]
B -->|No| J[Evaluate<br/>Other Options]
C -->|No| J
D -->|No| J
E -->|No| J
style A fill:#e3f2fd
style F fill:#e8f5e8
style G fill:#fff8e1
style H fill:#f3e5f5
style I fill:#fff3e0Hybrid Strategies
Modern AI applications often combine multiple techniques for optimal results:
- RAG + Prompt Engineering: Use RAG to access current information, then apply prompt engineering to format and present it effectively.
- Fine-tuning + RAG: Create a domain-specific model through fine-tuning, then enhance it with RAG for current information access.
- All Three Combined: Fine-tune for brand voice and behavior, use RAG for information access, and apply prompt engineering for specific formatting and interaction patterns.
5. Implementation Roadmap
Phase 1: Start Simple (Weeks 1-2)
- Begin with prompt engineering to understand your requirements
- Test different prompt strategies and document what works
- Identify gaps that prompting alone can’t address
Phase 2: Add Knowledge (Weeks 3-6)
- Implement RAG if you need external information access
- Start with a simple vector database and basic retrieval
- Iterate on document processing and retrieval strategies
Phase 3: Specialize (Months 2-4)
- Consider fine-tuning if you need consistent, specialized behavior
- Collect and prepare training data
- Start with parameter-efficient techniques before full fine-tuning
Phase 4: Optimize (Ongoing)
- Monitor performance and user feedback
- Refine your approach based on real-world usage
- Consider hybrid strategies for complex requirements
6. Common Pitfalls and How to Avoid Them
Prompt Engineering Pitfalls
- Over-complicating prompts: Start simple and add complexity only when needed
- Ignoring iteration: Expect to refine prompts based on results
- Unclear instructions: Be specific about what you want
RAG Pitfalls
- Poor document quality: Garbage in, garbage out – ensure your knowledge base is accurate and current
- Inadequate chunking: Test different ways of breaking up your documents
- Ignoring retrieval quality: Monitor what information is being retrieved and adjust accordingly
Fine-tuning Pitfalls
- Insufficient training data: You need substantial, high-quality examples
- Overfitting: Training too much on specific examples can reduce generalization
- Ignoring evaluation: Always test your fine-tuned model against your goals
7. Measuring Success
Key Metrics to Track
For All Approaches:
- Response accuracy and relevance
- User satisfaction scores
- Task completion rates
- Response time and system performance
For RAG Systems:
- Retrieval accuracy (are the right documents being found?)
- Source attribution quality
- Information freshness and currency
For Fine-tuned Models:
- Consistency with brand voice and guidelines
- Domain-specific accuracy
- Behavioral alignment with training objectives
8. Conclusion and Next Steps
The choice between prompt engineering, RAG, and fine-tuning isn’t always either/or. Understanding each technique’s strengths and limitations allows you to build more effective AI applications by choosing the right tool for each job.
Start with prompt engineering to understand your requirements and prove the concept. Add RAG when you need current or private information. Consider fine-tuning when you need specialized, consistent behavior that other techniques can’t provide.
Remember that the AI landscape is rapidly evolving. New techniques, better models, and improved tools are constantly emerging. Stay flexible in your approach and be prepared to adapt your strategy as new opportunities arise.
The most successful AI applications often combine multiple techniques thoughtfully, using each approach where it provides the most value while managing the overall complexity and cost of the system.