
Anthropic has just released Claude 3.7 Sonnet on February 24, 2025, positioning it as their most intelligent model to date. This new AI combines quick responses with step-by-step reasoning in a single “hybrid” system, making it especially powerful for coding, frontend development, and agentic use cases. Let’s explore what it offers, how it performs, and where it falls short.
1. What Is Claude 3.7 Sonnet?
Claude 3.7 Sonnet is Anthropic’s newest AI model, launched just days ago on February 24, 2025. Designed to excel in coding, front-end development and Agentic workflows (think task automation with tools), it builds on the success of Claude 3.5 Sonnet while introducing a groundbreaking hybrid reasoning system – surpassing top tier models like DeepSeek R1 and O3-mini , Unlike traditional models, it offers both instant answers and detailed, step-by-step problem-solving—though the latter is exclusive to paid users. With a focus on real-world software engineering over academic puzzles, it’s already making waves in the developer community.

- Release Date: February 24, 2025
- Core Strength: Coding, front-end tasks, and agentic use cases
- Availability: Free tier (basic mode) limited use and paid plans (extended features)
2. Key Features of Claude 3.7 Sonnet
This model packs a punch with features tailored for developers and businesses. Here’s what stands out:
- Hybrid Reasoning: Combines quick responses with optional extended thinking for complex tasks.
- Claude Code Tool: A terminal-based coding assistant for autonomous software tasks (API login required).
- Multimodal Support: Processes text and images, broadening its utility.
- Large Context Window: Handles up to 200K input tokens and outputs 8,192 tokens (64K in extended mode).
- 45% Fewer Refusals: Improved responsiveness compared to predecessors.
- Multilingual: Supports diverse language inputs for global reach.
3. In-Depth: Hybrid Reasoning Explained
The star of Claude 3.7 Sonnet is its hybrid reasoning capability—a first for Anthropic. This dual-mode system lets it switch between:
- Standard Mode: Fast, concise answers for straightforward queries (free tier).
- Extended Thinking Mode: Visible, step-by-step reasoning for tackling math, coding, or logic puzzles (paid plans only).
For example, in coding, it can debug a script instantly or break down the logic line-by-line, making it a dream for developers needing transparency. This flexibility sets it apart from rivals like OpenAI’s o1, which lean heavily on one reasoning style. However, locking extended mode behind a paywall might frustrate free-tier users.
- Why It Matters: Transparent reasoning boosts trust and usability.
- Use Case: Perfect for debugging or teaching complex concepts.
4. Benchmark Testing: How Claude 3.7 Sonnet Stacks Up
Claude 3.7 Sonnet shines in benchmark tests, particularly for coding and agentic tasks. Here’s the data:
4.1 SWE-Bench Verified (Real-World Coding):
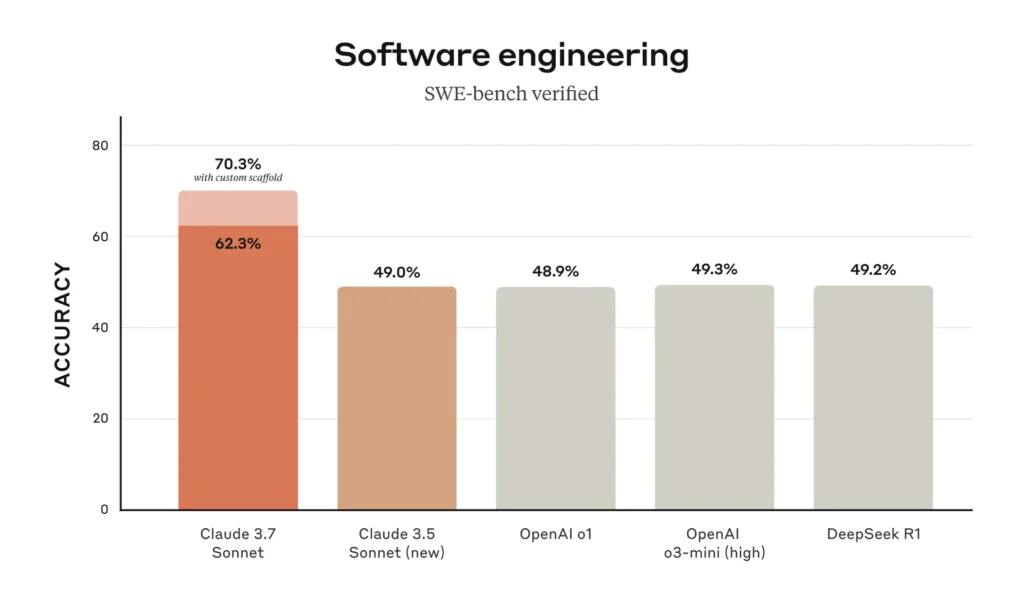
- 70.3% with extended scaffolding (vs. 49.0% for Claude 3.5 Sonnet)
- 63.7% standard mode (beats OpenAI o3-mini-high’s 49.3%)
- Claude 3.7 Sonnet achieves the highest accuracy at 62.3% on the SWE-bench for software engineering tasks.
- With a custom scaffold, its accuracy improves to an impressive 70.3%.
- It significantly outperforms other models like Claude 3.5 Sonnet, OpenAI o1, OpenAI o3-mini (high), and DeepSeek R1.
- This demonstrates Claude 3.7 Sonnet’s superior capability in handling complex software engineering challenges.
4.2 More benchmarks:
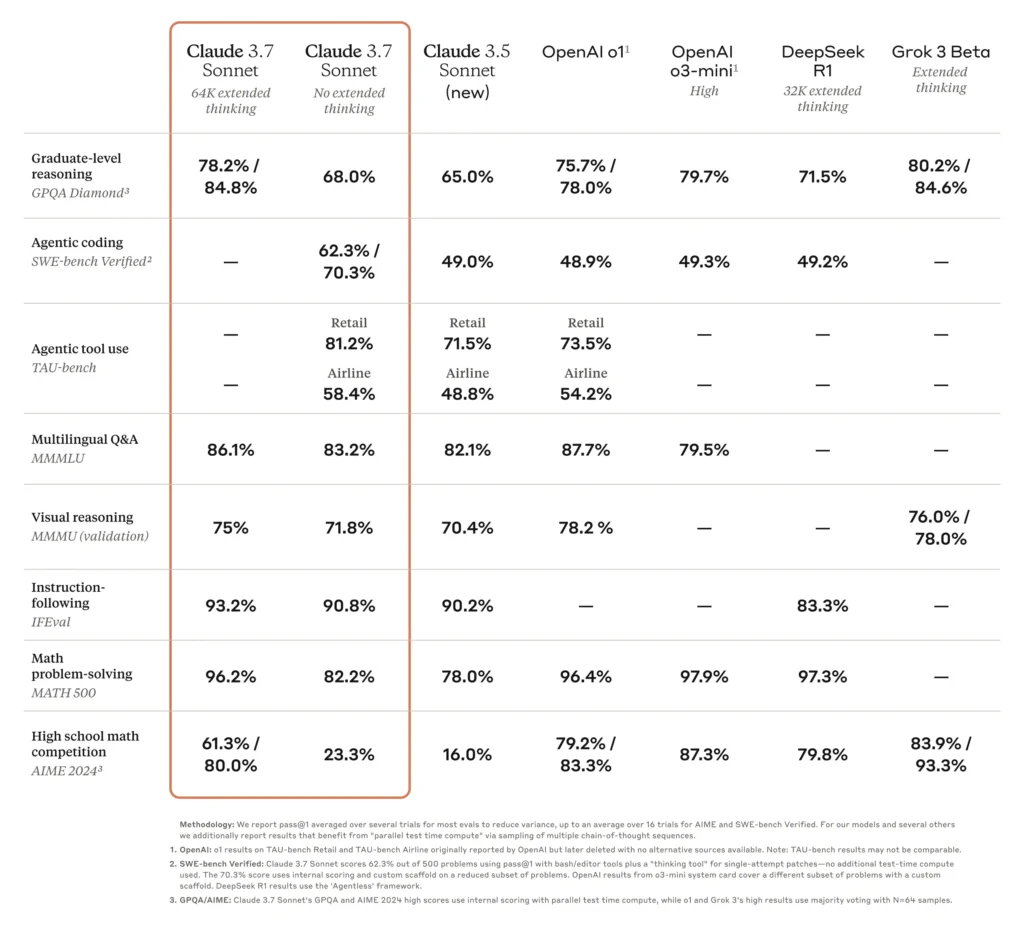
- Claude 3.7 Sonnet with 64k extended thinking achieves the highest accuracy at 84.8% on graduate-level reasoning (GPQA Diamond).
- It excels in agentic tool use (TAT-bench) with 81.2% accuracy, outperforming other models like Claude 3.5 Sonnet and OpenAI o1.
- Claude 3.7 Sonnet demonstrates strong performance in multilingual Q&A (MMLU) at 86.1% accuracy.
- In high school math competition (AIME 2024), it scores an impressive 80.0%, significantly surpassing Claude 3.5 Sonnet’s 16.0%.
These scores highlight its coding dominance and agentic prowess, though it trails slightly in pure math without extended mode. The 45% reduction in refusals also makes it more reliable than earlier models.
5. Agentic Use-case
TAU-bench is a benchmark that evaluates AI models on their ability to autonomously use tools in real-world scenarios, specifically in retail and airline industries, measuring accuracy in “Agentic tool use.”
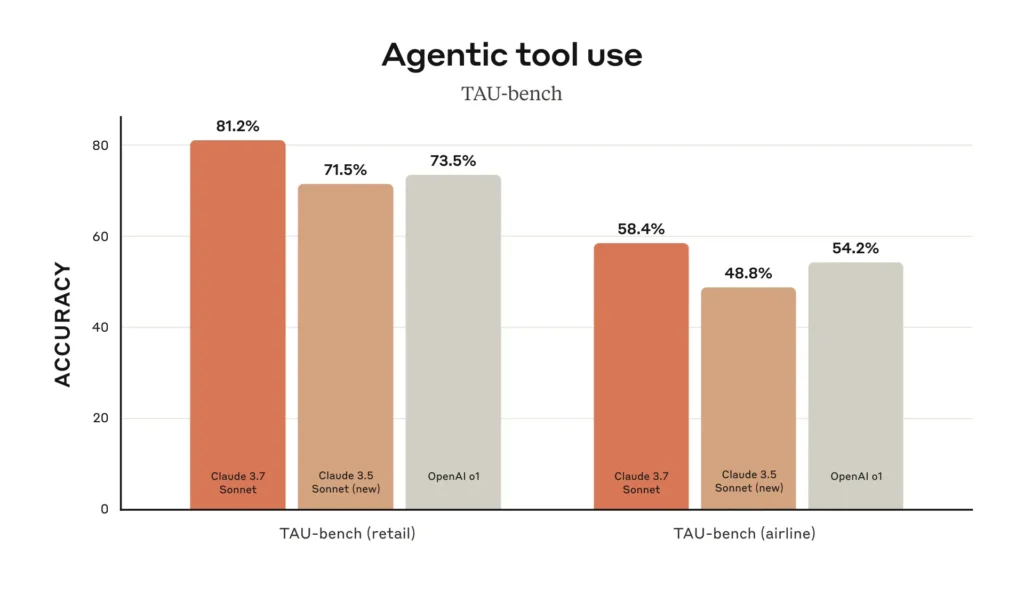
- Top Retail Performance: Claude 3.7 Sonnet leads in retail with 81.2% accuracy, surpassing Claude 3.5 Sonnet (new) at 71.5% and OpenAI o1 at 73.5%.
- Lower Airline Accuracy: In airlines, it scores 58.4%, outperforming Claude 3.5 Sonnet (new) at 48.8% but falling behind OpenAI o1 at 54.2%, highlighting sector challenges.
- Best Overall Average: With 69.8% average accuracy, it outperforms Claude 3.5 Sonnet (new) at 60.15% and OpenAI o1 at 63.85%, demonstrating strong tool use.
- Performance Gap: Its sharp decline from retail to airline tasks suggests it excels in structured domains like retail but struggles with complex scenarios like airlines.
6. Pricing Table and Comparison
Claude 3.7 Sonnet’s pricing varies by plan and API usage. Here’s a breakdown with comparisons:
| Model/Plan | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Context Window |
|---|---|---|---|
| Claude 3.7 Sonnet | $ 3 | $15 | 200k |
| OpenAI o3-mini | $ 1.10 | $ 4.40 | 200k |
| OpenAI O1 | $ 15 | $ 60 | 200k |
| Deepseek-R1 | $ 0.14 | $ 2.19 | 130k |
| Gemini Flash 2.0 | $ 0.10 | $ 0.40 | 1 Million |
Claude’s API is pricing is costly as compared to other models, and less context window then other models, also its thinking token are calculated in the context window only so less context window
7. Market Reaction: Buzz and Early Adoption
Since its launch, Claude 3.7 Sonnet has sparked excitement among developers and tech firms. Companies like Canva and Vercel are testing it, and its availability on Amazon Bedrock and Google Vertex AI signals strong enterprise interest. Social chatter praises its coding edge, but lacks at the high API cost and lack of web access. No downtime has been reported as of February 27, 2025—a good sign after Claude 3.5’s rocky patches in 2024.
- Positives: “Coding beast,” “hybrid mode is a game-changer.”
- Negatives: “Too expensive,” “needs internet access.”
8. Limitations of Claude 3.7 Sonnet
Despite its strengths, there are hurdles:
- High API Cost: $3/$15 per million tokens is steep vs. competitors.
- No Web Access: Static knowledge (cutoff late 2024) misses recent events.
- Thinking Mode Paywall: Extended reasoning locked for free users.
- Potential Reliability: No outages yet, but past models had issues.
- Limited Claude Code: Terminal-only, no UI—less user-friendly.
These gaps might push budget users or those needing real-time data toward alternatives like Grok 3 or ChatGPT.
9. Personal Take: Is Claude 3.7 Sonnet Worth It?
As an AI enthusiast, I’m impressed by Claude 3.7 Sonnet’s coding chops and hybrid reasoning—it’s a developer’s dream for practical projects. It performs exceptional at coding especially for frontend tasks. But the high API cost and lack of web access feel like missed opportunities, especially when rivals offer more for less. If you’re a Pro user or enterprise coder, it’s a no-brainer. For casual users? Maybe wait for a price drop or broader features. But as of search and more feature provided by other models the pro plan is not still worth it
10. Summary: Claude 3.7 Sonnet in a Nutshell
Claude 3.7 Sonnet, released February 24, 2025, is Anthropic’s smartest model yet, blending fast answers with deep reasoning for coding and agentic tasks. It dominates benchmarks like SWE-Bench and TAU-Bench integrates with platforms like Bedrock, and earns early praise from the market. However, its lack of internet access, and paywalled features temper its appeal. For developers, it’s a powerhouse; for others, it’s a premium option in a crowded field. And just like Sonnet 3.5 became the best choice for AI tools and for coding , Sonnet 3.7 model will be worth because it has same API price but with more intelligence.


Pingback: Make your AI smart with RAG (Retrieval-Augmented Generation) - Hitesh AI