

The artificial intelligence landscape continues to evolve at breakneck speed, with each new model pushing the boundaries of what’s possible. In this rapidly advancing field, Qwen3 has emerged as a groundbreaking addition to the competitive world of large language models (LLMs). Recently Released on April 29, 2025, this third-generation model from the Qwen family introduces several innovations that position it as a formidable competitor to industry giants like OpenAI’s o1 and o3-mini, Google’s Gemini-2.5-Pro, xAI’s Grok-3, and DeepSeek’s R1.
What makes Qwen3 particularly noteworthy is its hybrid thinking approach, extensive multilingual capabilities, and sophisticated architectural design that delivers impressive performance with remarkable efficiency. In this comprehensive analysis, we’ll explore how Qwen3 is changing the AI landscape and what its innovations mean for developers, researchers, and end users alike.
1. The Qwen3 Model Family: Power and Versatility
Qwen3 isn’t a single model but a carefully designed family of models that vary in size, architecture, and specific capabilities. This range offers users flexibility in choosing the right model for their particular needs, balancing performance against computational requirements.
| Model | Type | Total Parameters | Activated Parameters | Context Length | Features |
|---|---|---|---|---|---|
| Mixture of Experts (MoE) Models | |||||
| Qwen3-235B-A22B | MoE | 235B | 22B | 128K | 128 experts (8 activated), state-of-the-art performance |
| Qwen3-30B-A3B | MoE | 30B | 3B | 128K | 48 layers, 128 experts (8 activated), exceptional speed |
| Large Dense Models | |||||
| Qwen3-32B | Dense | 32B | 32B | 128K | Largest dense model in the family |
| Qwen3-14B | Dense | 14B | 14B | 128K | Powerful mid-sized option |
| Qwen3-8B | Dense | 8B | 8B | 128K | Balanced for performance and efficiency |
| Smaller Dense Models | |||||
| Qwen3-4B | Dense | 4B | 4B | 32K | Good performance with modest hardware requirements |
| Qwen3-1.7B | Dense | 1.7B | 1.7B | 32K | Compact yet capable model |
| Qwen3-0.6B | Dense | 0.6B | 0.6B | 32K | Ultra-lightweight for resource-constrained environments |
– Mixture of Experts (MoE) Models
The flagship models in the Qwen3 family utilize the Mixture of Experts (MoE) architecture, an approach that dramatically improves efficiency by activating only a small subset of parameters during inference:
- Qwen3-235B-A22B: The crown jewel of the family features a massive 235 billion total parameters with only 22 billion activated during inference. This model includes:
- 128 total experts with 8 activated during inference
- 128K token context length
- State-of-the-art performance across multiple benchmarks
- Qwen3-30B-A3B: A lighter MoE model with 30 billion total parameters and only 3 billion activated parameters, featuring:
- 48 layers
- 128 total experts with 8 activated at inference time
- 128K token context length
- Exceptional speed relative to its capabilities
- Performance that surpasses many larger dense models
– Dense Models
Alongside the MoE models, Qwen3 offers traditional dense models for various deployment scenarios:
- Large Dense Models:
- Qwen3-32B: The largest dense model in the family
- Qwen3-14B: A powerful mid-sized option
- Qwen3-8B: Balanced for performance and efficiency
- All feature 128K token context length
- Smaller Dense Models:
- Qwen3-4B: Good performance with modest hardware requirements
- Qwen3-1.7B: Compact yet capable model
- Qwen3-0.6B: Ultra-lightweight option for resource-constrained environments
- These models support a 32K token context length
All Qwen3 models are released under the Apache 2.0 license, making them accessible for both research and commercial applications—a significant advantage in a field where many top-performing models remain closed-source or have restrictive licenses.
2. Benchmark Performance: Measuring Up Against the Giants
One of the most compelling aspects of Qwen3 is how it performs against other leading models across a wide range of benchmarks. The results demonstrate that Qwen3 isn’t just competitive—it often outperforms models from much larger organizations with vastly greater resources.
– Flagship Model Performance
The Qwen3-235B-A22B model delivers exceptional results across diverse evaluation metrics:
- Reasoning and Problem-Solving:
- ArenaHard: Scores 95.6, outperforming OpenAI-o1’s 92.1 and OpenAI-o3-mini’s 89.0
- AIME’24: Achieves 85.7, stronger than OpenAI-o1’s 74.3
- AIME’25: Reaches 81.5, compared to higher scores from frontier models but still competitive
- Coding Capabilities:
- LiveCodeBench: Scores 70.7, edging out Gemini-2.5-Pro’s 70.4
- CodeForces: Achieves an impressive 2056 Elo Rating, outperforming Gemini-2.5-Pro’s 2001
- Aider: Shows strong performance in assisted programming tasks
- Agent Functionality:
- BFCL (Function calling benchmark): Scores 70.8 compared to Gemini-2.5-Pro’s 62.9
- Even the smaller Qwen3-32B dense model outperforms Gemini-2.5-Pro in this area with a score of 70.3
- General Knowledge:
- MMLU: Reaches 87, compared to Llama 4 Maverick’s 85
- MMLU Redux: Similarly outperforms Llama 4
- SuperGPQA: Scores 44 versus Llama 4’s 40
– Smaller Model Excellence
The Qwen3-30B-A3B model—with only 3 billion active parameters—demonstrates remarkable efficiency while still delivering strong performance:
- ArenaHard: Scores 91.0 (compared to Qwen2.5-72B-Instruct’s 81.2)
- AIME’24: Achieves 80.4 (dramatically higher than Qwen2.5-72B-Instruct’s 18.9)
- AIME’25: Reaches 70.0 (versus Qwen2.5-72B-Instruct’s 14.8)
- LiveCodeBench: Scores 62.6 (double the performance of Qwen2.5-72B-Instruct’s 30.7)
- GPQA Diamond: In independent benchmarks by Artificial Analysis, achieves around 70% accuracy with only 3 billion active parameters
These benchmarks illustrate that Qwen3 models aren’t just incrementally better than their predecessors—they represent a quantum leap in capabilities, especially considering their parameter efficiency.
3. Hybrid Thinking: The Revolutionary Approach
Perhaps the most innovative aspect of Qwen3 is its hybrid thinking capability—a feature that fundamentally changes how the model approaches problem-solving. This dual-mode operation allows Qwen3 to adapt its approach based on the complexity of the task at hand.
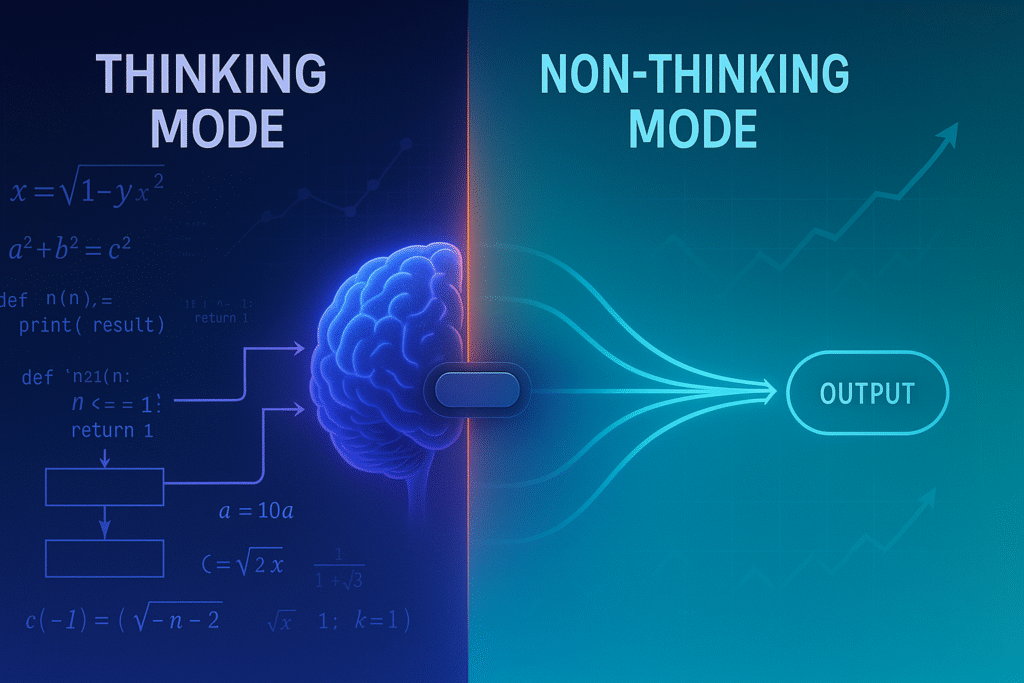
– Understanding the Two Modes
Qwen3’s hybrid thinking approach consists of two distinct operational modes:
- Thinking Mode:
- The model engages in explicit step-by-step reasoning
- Takes time to work through problems methodically
- Shows its chain of thought before arriving at conclusions
- Ideal for complex tasks in mathematics, coding, and logical reasoning
- Performance scales with the allocated “thinking budget” (computational resources)
- Non-Thinking Mode:
- Delivers quick, near-instant responses
- Skips explicit reasoning steps
- Performs consistently regardless of token allocation
- Perfect for straightforward questions and situations requiring immediate feedback
– The Impact of Thinking Budget
One of the most fascinating aspects of Qwen3’s hybrid thinking approach is how performance scales with the “thinking budget” (measured in thousands of tokens):
- AIME’24: Performance increases from approximately 60% in non-thinking mode to over 85% with a larger thinking budget
- AIME’25: Similar pattern of improvement, from around 55% to over 80%
- LiveCodeBench: Shows steady improvement from about 60% to over 70% as thinking tokens increase
- GPQA Diamond: Demonstrates significant gains from approximately 48% to 65% with increased thinking allocation
This scalability represents a major advancement in AI design philosophy. By allowing users to control the thinking/computation tradeoff, Qwen3 enables more efficient resource use while still delivering high-quality results when deep reasoning is necessary.
– Dynamic Control in Practice
The hybrid thinking approach is implemented in a user-friendly way, allowing dynamic switching between modes even within a single conversation:
- Simple commands like
/thinkand/no_thinktoggle between modes - Example usage:
- “How many r’s in strawberries?” (default thinking mode)
- “Then, how many r’s in blueberries? /no_think” (quick response mode)
- “Really? /think” (return to thinking mode for verification)
This flexibility makes Qwen3 particularly valuable for applications like coding assistance, where some tasks benefit from deep reasoning while others require quick responses. As noted in the transcribed content, Vibe coding represents a perfect use case, where complex feature development can use thinking mode while simple terminal commands can use non-thinking mode, optimizing both quality and speed.
4. Architectural Innovations: Mixture of Experts
The MoE architecture employed in Qwen3’s flagship models represents a significant advancement in efficient AI design. Unlike traditional dense models where all parameters are activated for every task, MoE models activate only a subset of specialized “expert” parameters based on the input.
– How MoE Works in Qwen3
The MoE implementation in Qwen3 involves:
- Expert Distribution: Parameters are organized into groups of specialized “experts”
- Routing Mechanism: A learned gating network determines which experts to activate for a given input
- Sparse Activation: Only a small fraction of parameters are used during any inference pass
– Efficiency Benefits
This architectural approach delivers several key benefits:
- Computational Efficiency: Using only 3-10% of parameters during inference dramatically reduces computational requirements
- Speed Advantages: The Qwen3-30B-A3B model (with only 3B active parameters) demonstrates remarkable speed even on consumer hardware
- Scaling Potential: The MoE approach allows the model to benefit from scale (235B total parameters) without corresponding inference costs
- Hardware Accessibility: Makes advanced AI capabilities available on more modest hardware configurations
Demonstrations show the Qwen3-30B-A3B model running surprisingly fast even on a Mac Studio with M3 Ultra chip, making this frontier-level AI accessible to individual developers and smaller organizations.
5. Multilingual Excellence: Breaking Language Barriers
Qwen3 stands out in the LLM landscape with its exceptional multilingual capabilities, supporting an impressive 119 languages and dialects across multiple language families.
– Language Coverage
The multilingual support spans a diverse range of language families:
- Indo-European: 59 languages including:
- English, French, German, Spanish, Italian
- Russian, Polish, Ukrainian
- Hindi, Bengali, Persian
- And dozens more European and Indo-Iranian languages
- Sino-Tibetan:
- Chinese (multiple variants including Mandarin, Cantonese)
- Burmese and other Tibeto-Burman languages
- Afro-Asiatic:
- Arabic (7 regional variants)
- Hebrew, Amharic, and other Semitic languages
- Berber languages
- Austronesian: 12 languages including:
- Indonesian, Malay
- Tagalog, Cebuano
- Javanese and other Southeast Asian languages
- Dravidian:
- Tamil, Telugu
- Kannada, Malayalam
- Other Major Languages:
- Japanese, Korean
- Thai, Vietnamese
- Turkish, Hungarian, Finnish
- Swahili and other African languages
This extensive language coverage makes Qwen3 particularly valuable for global applications, translation services, and cross-cultural communication platforms.
– Performance Across Languages
While most benchmarks focus on English-language performance, Qwen3 shows strong capabilities across its supported languages:
- Competitive performance in multilingual benchmarks
- Strong results in cross-lingual transfer tasks
- Some performance variation exists across language families, with generally stronger results in Indo-European languages
The multi-script capabilities (supporting Latin, Cyrillic, Arabic, Chinese characters, and many other writing systems) further enhance Qwen3’s utility in global contexts.
6. Training Methodology: From Data to Intelligence
The development of Qwen3 involved a sophisticated multi-stage training pipeline designed to maximize both breadth and depth of capabilities.
– Pre-training Process
The pre-training approach consisted of three distinct stages:
- Base Pre-training:
- Trained on approximately 36 trillion tokens (double the data used for Qwen2.5)
- Initial training on over 30 trillion tokens with 4K context length
- Focus on establishing fundamental language skills and general knowledge
- Knowledge Enhancement:
- Refinement with knowledge-intensive data (5 trillion additional tokens)
- Increased proportion of STEM, coding, and reasoning content
- Emphasis on specialized domains requiring deeper expertise
- Context Extension:
- Training on high-quality long-form content
- Progressive extension from 4K to 32K and ultimately 128K tokens
- Focus on maintaining coherence and consistency across longer texts
– Data Sources and Preparation
The training data incorporated several innovative approaches:
- Diverse Source Material:
- Web content spanning multiple domains
- PDF documents and structured text
- Academic and technical literature
- Code repositories and programming resources
- Quality Enhancement:
- Used Qwen2.5-VL to extract text from documents
- Leveraged Qwen2.5 to improve the quality of extracted content
- Created a virtuous cycle where each generation improves the next
- Synthetic Data Generation:
- Used Qwen2.5-Math and Qwen2.5-Coder to generate synthetic training data
- Created textbooks, question-answer pairs, and code snippets
- Augmented areas where natural data may be sparse
– Post-training Refinement
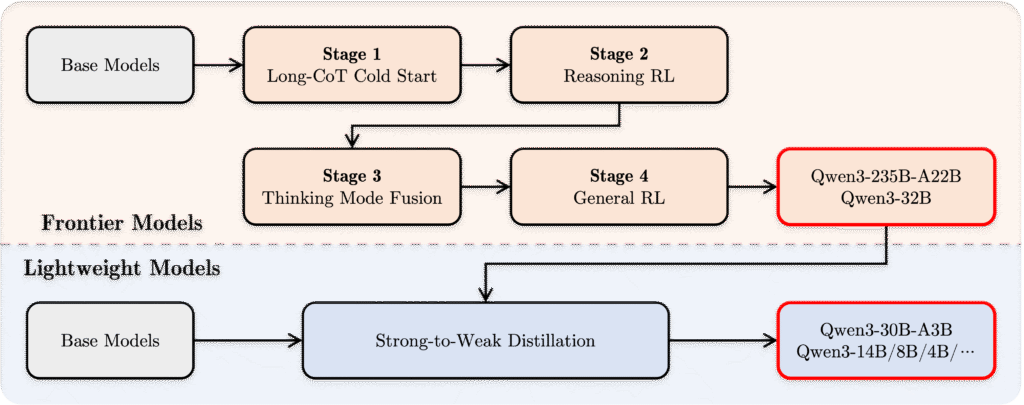
The four-stage post-training process was crucial for developing the hybrid thinking capabilities:
- Long Chain-of-Thought (CoT) Cold Start:
- Fine-tuning on diverse reasoning tasks
- Coverage of mathematics, coding, logical reasoning, and STEM problems
- Building fundamental step-by-step reasoning abilities
- Reasoning-based Reinforcement Learning:
- Scaling up computational resources for RL
- Implementing rule-based rewards
- Enhancing exploration and exploitation capabilities
- Thinking Mode Fusion:
- Integrating non-thinking capabilities with reasoning abilities
- Fine-tuning on a combination of long CoT data and instruction tuning data
- Creating a seamless blend between different operational modes
- General Reinforcement Learning:
- Applying RL across 20+ general domain tasks
- Strengthening general capabilities
- Correcting undesired behaviors
For smaller models, an additional “Strong-to-Weak Distillation” phase transferred knowledge from larger models to more compact ones, preserving capabilities while reducing size.
7. Practical Applications and Integration
Qwen3’s versatility and powerful capabilities make it suitable for a wide range of applications, and its open-source nature ensures broad accessibility.
– Deployment Options
The model can be deployed through multiple frameworks and platforms:
- Server Deployment:
- vLLM for creating OpenAI-compatible API endpoints
- Containerized solutions for cloud deployment
- Enterprise-grade serving options
- Local Development:
- Ollama for easy local setup
- LM Studio for user-friendly interface
- llama.cpp for optimized CPU inference
- MLX for Apple Silicon optimization
- KTransformers for specialized use cases
- Agentic Applications:
- Qwen-Agent for tool-calling capabilities
- Integration with existing agent frameworks
- Custom agentic implementations
– Code Implementation
Basic implementation with Hugging Face is straightforward:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switch between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
– Demonstrated Use Cases
Real-world demonstrations showcase Qwen3’s versatility:
- Enhanced Tool Use:
- Seamless integration with online resources
- Dynamic web content retrieval and processing
- Data visualization and analysis
- Computational Thinking:
- Mathematical problem-solving with step-by-step reasoning
- Code generation with explanations
- Debugging and code review
- System Interaction:
- File system organization and management
- Application control and automation
- Complex multi-step tasks involving multiple tools
One particularly impressive demonstration showed the model organizing a desktop by file type—creating appropriate folders and moving files accordingly—all through a fluid sequence of thinking, tool calls, and actions.
8. Independent Evaluations: Real-World Performance
Beyond the benchmarks provided by the Qwen team, independent evaluations offer additional perspective on the models’ capabilities.
– Artificial Analysis Benchmarks
Independent testing by Artificial Analysis provides valuable comparative data:
- GPQA Diamond (Scientific Reasoning):
- Qwen3-235B scores approximately 70%
- Places behind Gemini-2.5 Pro (84%) and O3
- Performs slightly below DeepSeek R1
- Shows strong performance relative to parameter count
- Parameter Efficiency Analysis:
- When plotting GPQA Diamond scores against active parameters, Qwen3 models show excellent efficiency
- Qwen3-30B-A3B (with only 3B active parameters) delivers performance comparable to much larger models
- Demonstrates superior performance-to-computation ratio compared to many competitor models
– Practical Experience Reports
Early user reports highlight several key aspects of real-world performance:
- Speed Observations:
- Qwen3-30B-A3B runs remarkably fast on consumer hardware like the Mac Studio M3 Ultra
- Code generation happens at impressive speeds
- Thinking mode maintains reasonable latency despite deeper processing
- Tool Usage Proficiency:
- Natural integration with various tools and APIs
- Smooth transition between thinking and tool calls
- Effective use of retrieved information
- Coding Capabilities:
- Strong performance in generating complete, working code
- Effective debugging and explanation
- Good translation between natural language requirements and functional implementations
9. Future Trajectory: From Models to Agents
The Qwen team has outlined an ambitious roadmap that points to a broader paradigm shift in AI development—moving from static models to dynamic agents.
– Key Development Directions
Future priorities for Qwen include:
- Scaling Enhancements:
- Continued architectural improvements
- More efficient parameter utilization
- Exploration of novel MoE configurations
- Context Extension:
- Further pushing beyond the current 128K token limit
- Improving long-range dependency modeling
- Enhancing memory mechanisms
- Multimodal Expansion:
- Integration of visual understanding
- Audio processing capabilities
- Cross-modal reasoning
- Advanced Reinforcement Learning:
- More sophisticated environmental feedback
- Better alignment with human preferences
- Enhanced exploration strategies
- Agent-Oriented Design:
- Transition from static models to interactive agents
- Development of long-horizon reasoning capabilities
- Better tool utilization and environmental interaction
– The Model-to-Agent Transition
The vision of transitioning from models to agents represents a fundamental shift in AI approach:
- Models respond to specific inputs with outputs based on learned patterns
- Agents interact with their environment, maintain state, and pursue goals over time
This evolution promises AI systems that can:
- Take initiative rather than just responding
- Maintain ongoing interactions
- Learn from their experiences
- Adapt to changing circumstances
- Better align with human needs and workflows
10. Conclusion: What Qwen3 Means for AI Development
Qwen3 represents more than just another incremental improvement in the LLM space—it embodies several important trends that are likely to shape the future of AI development.
– Key Innovations and Implications
Several aspects of Qwen3 stand out as particularly significant:
- Hybrid Thinking Approach: The dual-mode operation with controllable thinking budget offers a new paradigm for balancing depth and speed in AI responses. This approach likely previews how future systems will manage the tradeoff between computational resources and performance.
- Efficiency Through Architecture: The MoE approach demonstrates how thoughtful architecture design can dramatically improve efficiency without sacrificing capability. This trend toward more efficient models will be crucial as AI becomes more widespread.
- Open Innovation: Released under the Apache 2.0 license, Qwen3 makes frontier-level AI capabilities accessible to a broader community. This openness stands in contrast to the increasingly closed approaches of some major AI labs.
- Multi-stage Training: The sophisticated pre-training and post-training methodology shows how future models will likely be developed through increasingly complex pipelines rather than simple one-shot training.
- Agent-Oriented Design: The emphasis on tool use, reasoning, and environmental interaction points toward a future where AI systems function more as agents than as passive models.
– Looking Forward
As AI continues to evolve, Qwen3’s approach to balancing deep reasoning with quick responses points to a future where artificial intelligence can better adapt to the specific needs of different tasks and users. The journey from model to agent that the Qwen team envisions may well represent the next major paradigm shift in AI development—one that promises to make these systems even more helpful, versatile, and aligned with human needs.
Whether you’re building applications for coding assistance, multilingual communication, mathematical problem-solving, or general conversational AI, Qwen3 offers a compelling new option in the rapidly evolving landscape of large language models. Its open-source nature ensures that its innovations will benefit not just a single company or product, but the broader AI community as a whole.

