

In the fast-evolving world of artificial intelligence, striking a balance between performance and accessibility is a constant challenge. Enter Mistral Small 3.1, the latest open-source AI model from Mistral AI, released on March 17, 2025. With 24 billion parameters, this model combines cutting-edge capabilities with remarkable efficiency, making it a standout choice for developers, researchers, and businesses alike. Whether you’re building a chatbot, analyzing documents, or processing images on consumer-grade hardware, Mistral Small 3.1 promises to deliver top-tier performance without the need for expensive infrastructure.
In this detailed blog article, we’ll explore everything you need to know about Mistral Small 3.1—its key features, benchmark performance, practical applications, and how it’s redefining the AI landscape. Optimized for SEO and structured for readability, this guide will help you understand why this model is generating buzz in the AI community as of March 24, 2025.
1. What is Mistral Small 3.1?
Mistral Small 3.1 is an advanced, open-source AI model developed by Mistral AI, designed to excel in both text and image processing while remaining lightweight and efficient. Building on the foundation of its predecessor, Mistral Small 3, this iteration introduces significant upgrades, including an expanded context window of 128,000 tokens, enhanced multimodal understanding, and multilingual proficiency. Released under the permissive Apache 2.0 license, it’s freely available for use, modification, and distribution, making it a game-changer for democratizing AI technology.
With a compact design that runs on a single RTX 4090 GPU or a Mac with 32GB RAM (when quantized), Mistral Small 3.1 brings high-end AI capabilities to consumer hardware. This accessibility, paired with its robust performance, positions it as a versatile tool for a wide range of generative AI tasks, from conversational agents to on-device image analysis.
2. Key Features of Mistral Small 3.1
Mistral Small 3.1 is packed with features that make it a leader in its class. Here’s a breakdown of what sets it apart:
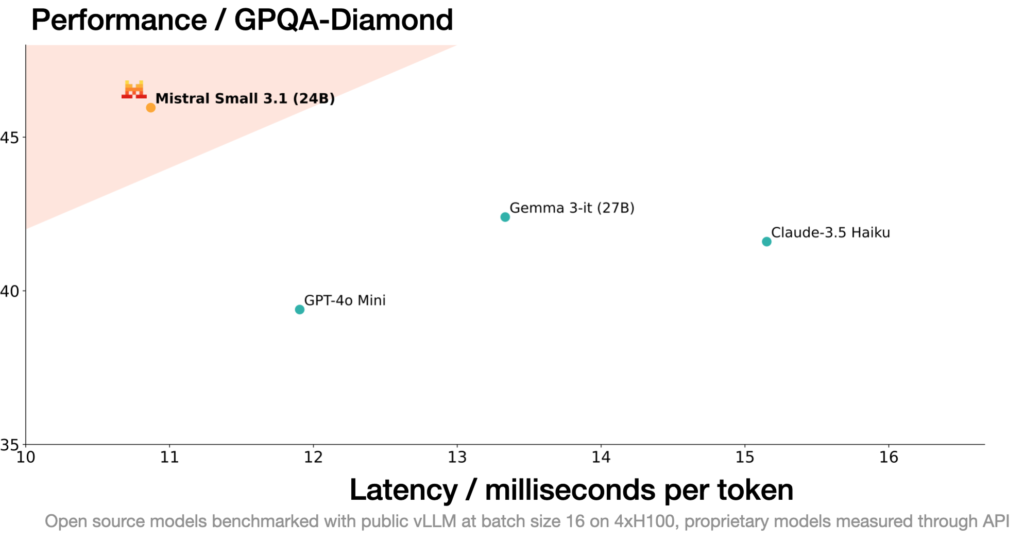
2.1. Lightweight and Efficient Design
- Runs seamlessly on consumer-grade hardware like an RTX 4090 or a 32GB RAM MacBook.
- Utilizes a Transformer-based architecture with Mixture of Experts (MoE) technology, activating only relevant parameters during inference for optimal efficiency.
- Offers 150 tokens per second inference speed, ensuring low-latency performance for real-time applications.
2.2. Multimodal Capabilities
- Processes both text and images, enabling tasks like document analysis, visual question answering, and image classification.
- Employs advanced encoding mechanisms to handle multiple image sizes and integrate visual data with textual context.
2.3. Expanded Context Window
- Supports up to 128,000 tokens, ideal for long-context tasks such as document summarization, in-depth analysis, and extended conversations.
- Uses sliding window attention and rolling buffer cache techniques to manage long sequences efficiently.
2.4. Multilingual Proficiency
- Excels in dozens of languages, including English, French, German, Spanish, Chinese, Japanese, Arabic, and more.
- Outperforms peers in multilingual benchmarks, making it a go-to choice for global applications.
2.5. Agent-Centric Features
- Offers native function calling and JSON outputting, enhancing its utility in automated workflows and agent-based systems.
- Fine-tunable for specialized domains like legal, medical, or technical support.
2.6. Open-Source Accessibility
- Released under the Apache 2.0 license, encouraging community innovation and customization.
- Available on platforms like Hugging Face, Google Cloud Vertex AI, and Mistral AI’s La Plateforme.
3. Performance Benchmarks: How Does Mistral Small 3.1 Stack Up?
Mistral Small 3.1 has been rigorously tested against leading models in its category, consistently delivering competitive or superior results. Here’s a snapshot of its performance based on the instruction-finetuned version (sourced from Hugging Face and independent reviews):
| Category | Mistral Small 3.1 | Gemma 3 27B | GPT-4o Mini | Claude 3.5 Haiku |
| MMLU | 80.62% | 76.90% | 82.00% | 77.60% |
| HumanEval | 88.41% | 87.80% | 87.20% | 88.10% |
| Vision | 64.00% | 64.90% | 59.40% | 60.50% |
| Multilingual | 71.18% | 70.19% | 70.36% | 70.16% |
| Long Context | 81.20% | 66.00% | 65.80% | 91.90% |
Key Takeaways :
- Text Performance: Matches or exceeds models like GPT-4o Mini in coding (HumanEval) and general knowledge (MMLU).
- Vision: Leads in MathVista and performs strongly in MMMU, showcasing its multimodal strength.
- Long Context: Outshines most peers in LongBench v2 and RULER 128K, thanks to its massive context window.
- Latency: Boasts a 0.46-second Time to First Token (TTFT), faster than the average for its class.
4. Practical Applications of Mistral Small 3.1
Mistral Small 3.1’s versatility makes it suitable for a wide array of use cases across industries. Here are some practical applications:
4.1. Conversational AI and Virtual Assistants
- Powers fast, context-aware chatbots for customer support or personal assistance.
- Maintains coherence in extended conversations with its 128k-token context window.
4.2. Document Processing and Verification
- Analyzes and summarizes long documents with ease.
- Ideal for compliance checks, knowledge management, and automated workflows.
4.3. Image-Based Applications
- Performs visual inspection for quality control in manufacturing.
- Supports object detection in security systems and image-based customer support.
4.4. Diagnostics and Specialized Domains
- Fine-tunable for medical diagnostics, legal advice, or technical support.
- Processes images and text for comprehensive analysis in healthcare or engineering.
4.5. On-Device Processing
- Runs locally on consumer hardware, ensuring privacy for sensitive data.
- Perfect for hobbyists, small businesses, or organizations avoiding cloud dependency.
4.6. Educational Tools and Content Creation
- Generates interactive learning materials and personalized feedback.
- Assists in coding, math reasoning, and multilingual content development.
5. How to Access and Use Mistral Small 3.1
Getting started with Mistral Small 3.1 is straightforward, thanks to its open-source nature and multiple deployment options:
Availability :-
- Hugging Face: Download the Base or Instruct versions (Base | Instruct).
- Mistral AI’s La Plateforme: Access via API for seamless integration.
- Google Cloud Vertex AI: Available now, with NVIDIA NIM and Microsoft Azure AI Foundry support coming soon.
- Local Deployment: Use tools like Ollama or vLLM for easy setup on consumer hardware.
Hardware Requirement :-
- Minimum: RTX 4090 (24GB VRAM) or Mac with 32GB RAM (quantized).
- Fine-Tuning: Tools like Unsloth optimize fine-tuning, requiring just 18GB VRAM.
6. Why Mistral Small 3.1 Matters
Mistral Small 3.1 stands out for several reasons:
- Efficiency: Runs on consumer hardware, lowering the barrier to entry.
- Versatility: Handles text, images, and multiple languages with ease.
- Open-Source: Encourages innovation and customization under Apache 2.0.
- Performance: Competes with models like GPT-4o Mini while staying lightweight.
By bridging the gap between power and accessibility, it empowers developers and businesses to build advanced AI solutions without breaking the bank.
7. Summary
Mistral Small 3.1, released on March 17, 2025, is more than just an AI model—it’s a testament to the potential of open-source innovation. With its 24 billion parameters, 128,000-token context window, and multimodal capabilities, it delivers exceptional performance in a compact package. Whether you’re a developer crafting a chatbot, a business analyzing documents, or a researcher pushing AI boundaries, this model offers the tools you need to succeed.
As the AI landscape continues to evolve, Mistral Small 3.1 is poised to lead the charge in lightweight, efficient, and versatile AI solutions. Download it from Hugging Face or integrate it via API , and join the growing community redefining what’s possible with AI.

