In the fast-evolving landscape of artificial intelligence (AI), Retrieval-Augmented Generation (RAG) stands out as a revolutionary approach that enhances how machines understand and respond to human queries. By combining the precision of information retrieval with the fluency of generative language models, RAG systems deliver accurate, contextually rich, and up-to-date answers. Whether you’re curious about cutting-edge AI technologies or looking to implement RAG in your business, this blog will guide you through its definition, importance, detailed workings, real-life applications, and more—all while being optimized for search engines.
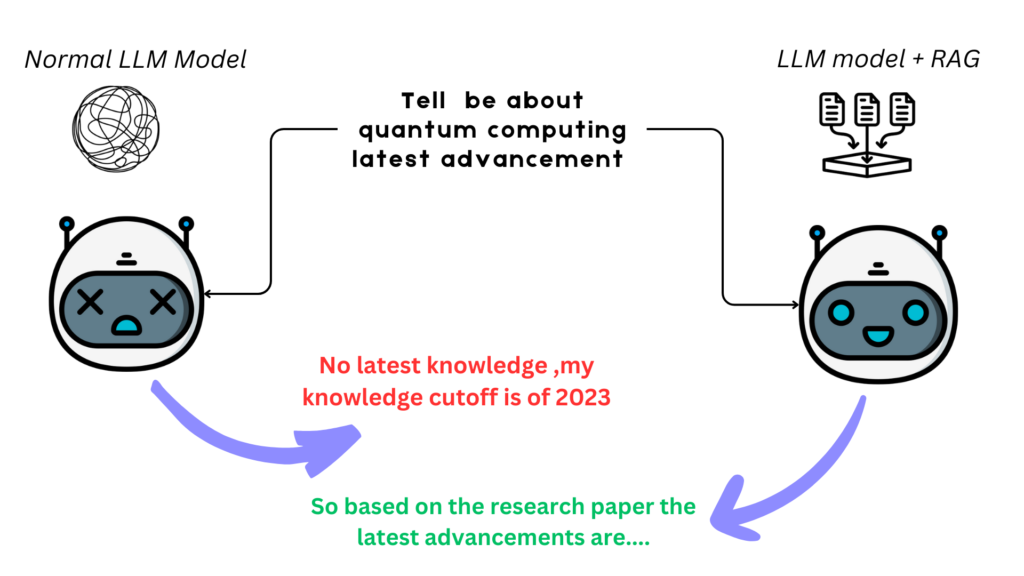
1. What is RAG?
Retrieval-Augmented Generation (RAG) is a hybrid framework in natural language processing (NLP) that integrates two powerful techniques:
- Retrieval: Searching and fetching relevant information from a large external dataset, such as documents, articles, or a knowledge base.
- Generation: Crafting human-like responses using a language model, such as GPT, deepseek or any other LLM, based on the retrieved data.
Unlike traditional language models that rely solely on pre-trained, static knowledge, RAG systems dynamically pull in external information to inform their responses. Imagine giving an AI a vast library and the ability to flip through its pages before answering your question—that’s RAG in action. This synergy ensures responses are not only fluent but also grounded in real, current data, making it a game-changer for knowledge-intensive tasks.
2. Why is RAG Important?
RAG addresses critical limitations of standalone language models, making it an essential advancement in AI. Here’s why it matters:
- Overcoming Static Knowledge: Traditional models, trained on fixed datasets, can’t keep up with new developments—like a product launch in 2025 if their training ended in 2023. RAG retrieves fresh data, keeping answers relevant.
- Reducing Hallucinations: Without access to real-time facts, models sometimes “guess” and produce plausible but incorrect answers (hallucinations). RAG grounds responses in verifiable data, boosting accuracy.
- Enhancing Specificity: For niche or detailed queries, traditional models may lack depth. RAG fetches precise information, tailoring responses to the exact context.
- Driving Innovation: From customer support to research, RAG’s ability to deliver reliable, context-aware answers is transforming industries.
In short, RAG empowers AI to be smarter, more reliable, and adaptable—crucial qualities in a world where information changes rapidly.
3. Detailed Working of RAG: Step-by-Step
RAG systems operate through a seamless process that transforms raw data into insightful answers. Below, we break it down into five named steps, enriched with explanations and bullet points for clarity.
3.1 Building the Foundation—Data Injection into a Vector Database :
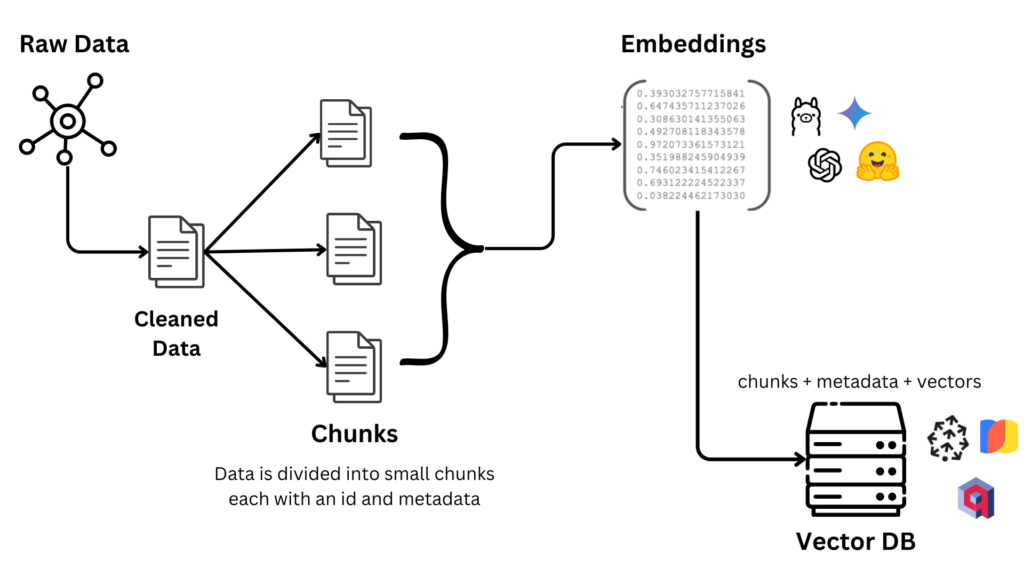
Step 1: Raw Data
This initial step involves gathering unstructured or semi-structured raw data from various sources, such as text documents, databases, APIs, or web scraping. . The objective is to collect all relevant data that will be stored in a vector database. The data can come in various formats like PDFs, JSON, CSV, or plain text, depending on the source, and serves as the foundation for subsequent processing.
Example:
Creating a research Chatbot using RAG system for all my research papers
- Sources: Text documents, Pdfs, web scraping.
- Data Formats: PDFs, JSON, CSV, plain text.
Step 2: Data Cleaning (optional)
Some times Raw data can contain unwanted links or text that we don’t need to save. The raw data is processed to remove noise, inconsistencies, duplicates, and irrelevant information. Techniques such as text normalization ,and deduplication are applied. The goal is to produce cleaner, more consistent data that is suitable for further processing. This step often leverages tools like Python libraries or regular expressions to ensure the data meets quality standards. This step is optional
Step 3: Data Chunking
The cleaned data is segmented into smaller, manageable pieces called chunks to optimize processing and storage in a vector database. Each chunk is assigned a unique identifier (ID) and metadata (e.g., source, review ID or any field) to preserve context and enable traceability. Chunking can be performed by splitting the data into sentences, paragraphs, or fixed-size segments, depending on the application’s requirements. This granularity enhances the efficiency of subsequent steps like embedding generation and similarity searches.
There are several types of chunking methods you can use :
- Fixed Size Chunking
- Recursive Chunking
- Document Based Chunking
- Semantic Chunking
- Agentic Chunking
- Hybrid Chunking (combining multiple techniques with custom algorithm )
Example:
Suppose you get a big text with 4000 words , you cannot embed this whole document at once, we need to divide into small chunks which are just original text divided into small parts
For 10 chunks, the previous text there will be 400 words per chunk.
Step 4: Generating Embeddings
Each chunk is transformed into a numerical vector known as an embedding, which captures the semantic meaning of the text in a high-dimensional space. This is achieved using models such as BERT, Sentence-BERT, or OpenAI’s embeddings API. The resulting embeddings are dense vectors (e.g., 768 dimensions or higher depending on model) that represent the chunk’s content numerically, enabling similarity comparisons in the vector database. The process involves inputting the chunk into the model and output is the vector output.
Example:
For the chunk “We will need workers to make and maintain all those new robots and artificial intelligence systems. Artificial intelligence has a way to go before it runs our lives.“,
an embedding model might produce:[0.347891, 0.123456, ..., 0.987654] (simplified 768-dimensional vector).
For “but battery life is poor", it might generate:
[0.234567, 0.876543, …, 0.654321].
- Models: BERT, Sentence-BERT, OpenAI embeddings.
- Process: Input text chunk → Model inference → Vector output.
- Output: Numerical vectors (embeddings) representing each chunk, paired with metadata.
Note : the original text , along with metadata and vector embeddings need to be stored in database
Step 5: Storing in Vector Database
The final step involves injecting the chunks, their metadata, and corresponding embeddings into a vector database designed for high-dimensional data, such as Pinecone, Faiss, or Weaviate. The database indexes the vectors for efficient similarity searches. Each entry typically includes the vector, the original chunk, and metadata, enabling fast retrieval based on similarity metrics like cosine similarity . This step completes the foundation for applications like semantic search.
Example:
The chunks and embeddings from Step 4 are stored in a vector database:
- Entry 1: {id: 1, chunk: “great product”, vector: [0.347891, 0.123456, …], metadata: {review_id: 1, source: customer_feedback}}
- Entry 2: {id: 2, chunk: “but battery life is poor”, vector: [0.234567, 0.876543, …], metadata: {review_id: 1, source: customer_feedback}}
- Databases: Pinecone, Faiss, Weaviate.
- Storage: Vectors, original chunks, metadata.
- Querying: Retrieve similar vectors using similarity metrics.
3.2 Retrieval and Generation :
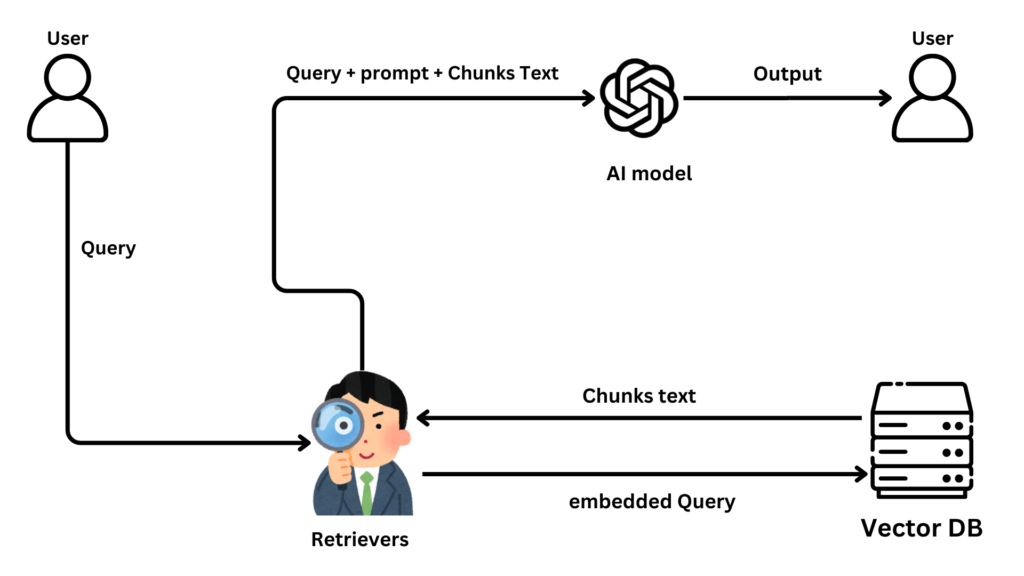
Step 1: User Query
The RAG process begins when a user asks a question, setting the system in motion.
- The user submits a query (e.g., “What’s the battery life of the Galaxy S24?”), which is received and prepared for processing.
- Key Details:
- A simple, natural language question from the user,
- This query acts as the trigger that starts the retrieval and generation process.
Step 2: Retrievers at Work—Fetching Relevant Data
Retrievers are the functions which searches a database to find information that matches the user’s query.
- The query is converted into a format (a vector embedding just like in data injection ) and compared with stored data in the “Vector DB” to retrieve relevant chunks.
- the embedding of both “Query” and “all text chunks” are compared and using cosine similarly, the most similar chunks text to the Query are retrieved
- You can set “k” which is number of texts similar to the query (more the number of text, more data will be retrieved )
- Key Details:
- Query Embedding: The query is turned into a vector embedding
- Similarity Search: The system finds the best-matching data using a method like cosine similarity, from the “Vector DB.”
- Output: It fetches the most relevant pieces of information to the query (e.g., “The phone has a battery that lasts up to 30 hours”).
Step 3: AI Integration—Crafting the Response
The retrieved data is combined with the query and the prompt is sent to the AI model to create a clear answer.
- The query, retrieved chunks, and a prompt are fed into a generative AI (e.g., GPT, Deepseek, Claude) to produce a natural response.
- Key Details:
- The system combines the “Query”, “Chunks text” and a prompt (e.g., “Answer clearly”)
- Processing: The AI blends the information into a coherent response, focusing on what’s relevant.
- Flexibility: It adjusts the answer to be accurate and easy to understand.
- Example: From the chunk, the AI generates: “The Galaxy S24’s battery lasts up to 30 hours”.
Step 4: Delivering the Output—Presenting the Answer
The final answer is sent back to the user in a clear, concise format.
- Example: The user receives, “The Samsung Galaxy S24 has a battery life of up to 30 hours on a single charge,”
- Benefit: The user gets a quick and precise and human like answer tailored to their question.
The AI model’s response is delivered to the user as a polished, user-friendly answer.
4. Real-Life Use Cases of RAG Systems
RAG’s versatility shines in practical applications. Here are three detailed examples with simple scenarios:
4.1 Customer Support Chatbots
- Scenario: A customer asks, “Why is my printer offline?”
- How RAG Helps: The system retrieves the latest troubleshooting guide from the company’s vector database (e.g., “Check the Wi-Fi connection”) and generates a step-by-step fix.
- Benefit: Provides instant, accurate help, reducing wait times and improving satisfaction.
- Real-World Impact: Companies like tech support providers use RAG to handle thousands of queries daily with precision.
4.2 Research Assistants
- Scenario: A student asks, “What are the latest advancements in quantum computing?”
- How RAG Helps: It fetches recent articles and papers from a vector database, then summarizes key points like “Google’s new quantum chip in 2023 boosts processing speed.”
- Benefit: Saves time and delivers current, credible insights tailored to the query.
- Real-World Impact: Universities and research labs use RAG to accelerate discovery and learning.
4.3 Content Creation Tools
- Scenario: A marketer needs a blog on “AI trends in 2024.”
- How RAG Helps: The system pulls recent reports and trends from a database, generating a draft like “RAG systems are leading AI innovation in 2024.”
- Benefit: Speeds up content production while ensuring accuracy and relevance.
- Real-World Impact: Media agencies leverage RAG to create high-quality, fact-based articles efficiently.
These examples highlight how RAG enhances AI’s ability to tackle real-world challenges with precision and speed.
5. Advanced RAG Techniques
5.1 Multi-Query RAG
- Generate multiple reformulations of the original query to retrieve a more diverse set of relevant documents.
- Combine results from these different queries to provide more comprehensive information.
5.2 Hypothetical Document Embeddings (HyDE)
- Generate a hypothetical answer to the query first
- Embed this hypothetical document and use it to retrieve similar documents
- This approach often retrieves more relevant information for complex queries
5.3 Self-Querying RAG
- The system analyzes the query to determine what metadata filters to apply
- Combines semantic search with structured metadata filtering
- Results in more precise and targeted document retrieval
5.4 Recursive RAG
- Uses multiple rounds of retrieval and generation
- Initial response is analyzed to identify knowledge gaps
- Additional queries are generated to fill these gaps
- Final response synthesizes all retrieved information
6. Challenges and Considerations in RAG Implementation
While RAG systems are transformative, they also present unique challenges:
- Computational Overhead: Retrieving and processing large amounts of data can be resource-intensive, potentially leading to higher latency and costs.
- Quality of Retrieved Information: The system is only as good as the data it retrieves; poor-quality data leads to poor-quality responses.
- Context Window Limitations: When too many documents are retrieved, they may exceed the context window of the LLM, requiring effective prioritization strategies.
- Semantic Search Limitations: Current embedding models may struggle with complex queries or nuanced semantic relationships.
- Evaluation Challenges: It’s difficult to objectively measure RAG system quality across different use cases and domains.
7. Integration with Multi-Modal Systems and Cross-Domain Applications
As AI technology evolves, RAG systems can be integrated with various data types and applications:
- Cross-Domain Integration: Merging data from different fields (e.g., finance, healthcare, legal) to provide comprehensive answers.
- Multi-Modal Capabilities: Expanding beyond text to include images, videos, and sensor data, thus broadening the scope of RAG applications.
- Customizable Frameworks: Allowing businesses to tailor RAG systems to their specific industry needs through modular architectures and plug-in support.
8. Summary: The Power and Promise of RAG
Retrieval-Augmented Generation (RAG) is a transformative technology that bridges the gap between static AI knowledge and dynamic, real-world data. Here’s a recap of its essence:
Looking ahead, RAG’s potential is vast. As vector databases grow more efficient and language models become smarter, RAG will drive AI toward greater reliability and adaptability. Whether you’re a developer, business owner, or AI enthusiast, understanding RAG opens the door to a future where machines don’t just talk—they truly inform.